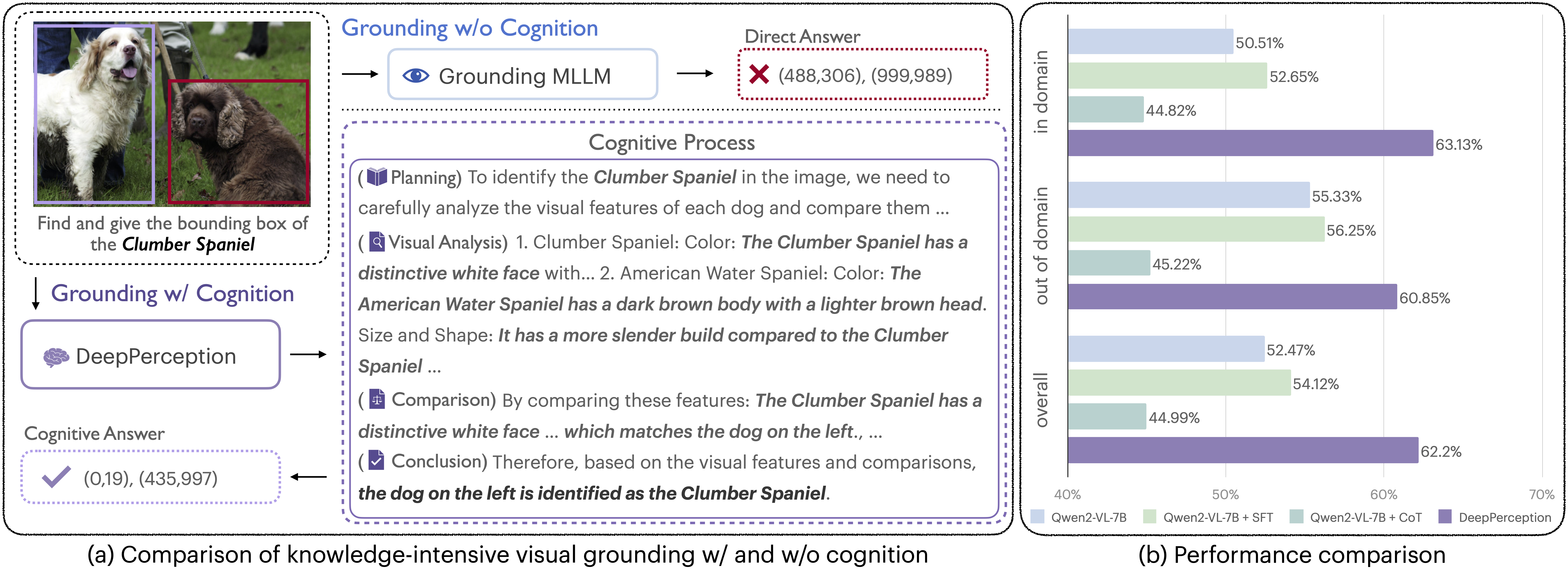
Figure 1: (a) DeepPerception employs knowledge-driven reasoning to derive answers, while the baseline model directly outputs predictions without cognitive processing. (b) DeepPerception demonstrates superior cognitive visual perception capabilities that cannot be elicited in the foundation model through simplistic zero-shot CoT prompting.
Abstract
Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis.
To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both finegrained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench, a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases.
Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08% accuracy improvements on KVG-Bench and exhibiting +4.60% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research.
KVG-Bench
Figure 2: (a) KVG-Bench images contain multiple subordinate-category entities (e.g., Boeing 777, 767, 757, 747, 737, 727, 717, 707 from top to bottom in the left image); (b) KVG-Bench exhibits high diversity across categories and entities.
Task Definition
The task of knowledge-intensive visual grounding (KVG) is to predict a bounding box $B = f_\theta (X_I , X_T )$ through joint understanding of visual input $X_I$ and textual query $X_T$ , requiring fine-grained alignment between multimodal representations. While sharing structural similarities with referring expression comprehension (REC), this task significantly elevates the challenge beyond standard REC tasks. As exemplified in Fig. 2 (a), the queries of KVG involve fine-grained entity specifications (e.g., “Boeing 747”) rather than generic categories such as “aircraft”. Additionally, each image contains multiple objects from the same category of the target object (e.g., multiple aircraft in a single image). This setup requires both expert-level knowledge and advanced perceptual and reasoning abilities to pinpoint the precise features that distinguish the target from similar objects.
Benchmark Construction
KVG-Bench comprises 1,336 test instances spanning 10 categories with 882 distinct entities, as statistically visualized in Fig. 2 (b).
The construction includes two key parts: image collection and data annotation.
We designed a meticulous collection process to ensure the diversity and complexity of the images.
First, we carefully selected 10 categories from the field of fine-grained visual recognition (FGVR) that are suitable for visual grounding, excluding categories which are challenging for object localization such as "sports" and "scene".
Second, an entity list for each category was systematically developed through initial extraction of fine-grained labels from existing datasets, followed by comprehensive enrichment of entity names via ChatGPT-assisted expansion.
We then retrieved web images using these entity names as search queries, enforcing strict quality criteria: each image must contain at least two entities from the same category with clear visual disparities.
The annotation process prioritized quality control.
Five annotators manually annotated each image with bounding boxes and entity labels by cross-referencing contextual information (e.g. caption, webpage metadata) with authoritative sources (e.g., Wikipedia entries) to verify entity identities.
To ensure consistency, the annotations underwent independent re-evaluation by annotators who did not participate in the initial labeling, with conflicting cases cross-verified through multi-annotator reconciliation and persistently inconsistent instances eliminated to ensure annotation accuracy.
By integrating strict validation protocols and expert-aligned annotation workflows, KVG-Bench sets a new standard for evaluating cognitive visual perception in multimodal systems.
Human Evaluation
To assess the difficulty of KVG-Bench, we conducted human evaluations with 11 non-expert volunteers under two experimental settings: Closed-Book (no external resources) and Open-Book (single Wikipedia query/case to simulate expert-level knowledge integration). Participants were randomly assigned several categories, with each category at least five evaluators to mitigate knowledge bias. The evaluation results, as shown in Tab. 1, reveal significant performance differences between settings. The Open-Book Setting demonstrated significant performance elevation (78.83% accuracy) compared to Closed-Book results (56.41%). This validates that KVG-Bench requires synergistic integration of expert-level knowledge and fine-grained visual comparison, positioning it as a meaningful testbed for advancing cognitive visual perception in MLLMs.
Method
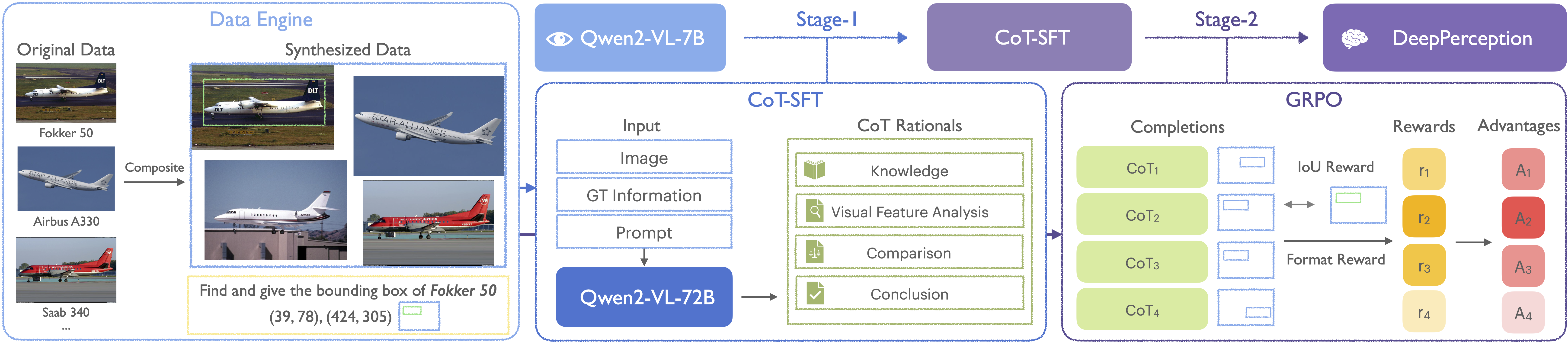
Figure 3: Overview of the proposed data engine and two-stage training framework.
Chain-of-Thought Supervised Fine-Tuning

Figure 4: Example of Chain-of-Thought data generated by Qwen2-VL-72B.
The primary objective of the first stage training is to endow models with visual perception-oriented cognitive capabilities through synthesized CoT training data. This process fosters an initial cognitive-perceptual synergy by explicitly modeling reasoning trajectories in the KVG task while establishing fundamental knowledge association patterns for subsequent optimization. Specifically, we leveraged the powerful Qwen2-VL-72B model to generate CoT reasoning data. As illustrated in Fig. 4, we generated CoT rationales by inputting images, ground-truth annotations (labels and bounding boxes), and CoT reasoning prompts into the model. This process synthesizes reasoning chains that combine the model's domain knowledge with human-like cognitive processes (e.g., iterative hypothesis verification through joint domain knowledge and visual feature analysis). We then performed SFT on the Qwen2-VL-7B model using these data, yielding the stage-1 model with foundational cognitive visual perception capabilities. This model demonstrates preliminary abilities to integrate domain knowledge and generate stepwise reasoning chains for visual grounding, which serves as a stable foundation for the second-stage reinforcement learning training. This approach bridges the gap between raw perception and expert-level cognition, enabling models to emulate human-like visual perception through knowledge-visual co-verification.
Perception-oriented Reinforcement Learning
Following the initial CoT-SFT training, we conducted reinforcement learning using a separate subset of training data to further enhance the model's perception capabilities, building upon its acquired cognitive visual perception foundation. As illustrated in Fig. 3, we adopted GRPO following Guo et al, which optimizes the policy model by sampling a group of outputs to a question and calculating a group-relative advantage instead of a critic model. To adapt GRPO for visual grounding tasks, we designed a rule-based reward system and performed data filtering on the training data using the stage-1 model.
Training Objective. Let $q$ denote the question and ${o_1, . . . , o_G}$ denote the sampled outputs from the old policy model πθold , then the optimization objective of policy model $\pi_{\theta}$ can be formally defined as:
$\mathcal{J}_{G R P O}(\theta)=\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{o l d}}(O \mid q)\right]\frac{1}{G} \sum_{i=1}^G \left(\frac{\pi_\theta\left(o_i \mid q\right)}{\pi_{\theta_{o l d}}\left(o_i \mid q\right)} A_i - \beta \mathbb{D}_{K L}\left(\pi_\theta| | \pi_{r e f}\right)\right),$
$\mathbb{D}_{K L}\left(\pi_\theta| | \pi_{r e f}\right)=\frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-\log \frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-1$
where $\varepsilon$ and $\beta$ are hyper-parameters and $A_i$ is the advantage computed based on a group of rewards $\{r_1, \ldots, r_G\}$ corresponding to the outputs of each group:
$A_i=\frac{r_i-mean(\{r_1, \ldots, r_G\})}{std(\{r_1, \ldots, r_G\})}$
Reward Modeling. We adopted a rule-based reward system specifically tailored for visual grounding tasks, comprising two types of rewards: Intersection over Union (IoU) reward and Format reward. The IoU reward evaluates the spatial alignment between predicted bounding boxes and ground-truth annotations. Given the ground-truth bounding box $B$ and the predicted bounding box $\tilde{B}$, the IoU reward is formally defined as:
$R_{\mathrm{IoU}}= \begin{cases} \operatorname{IoU}(B, \tilde{B}), & \text { if } \operatorname{IoU}(B, \tilde{B}) \geq \tau \\ 0, & \text { otherwise } \end{cases}$
Experiment & Analysis
Main Results
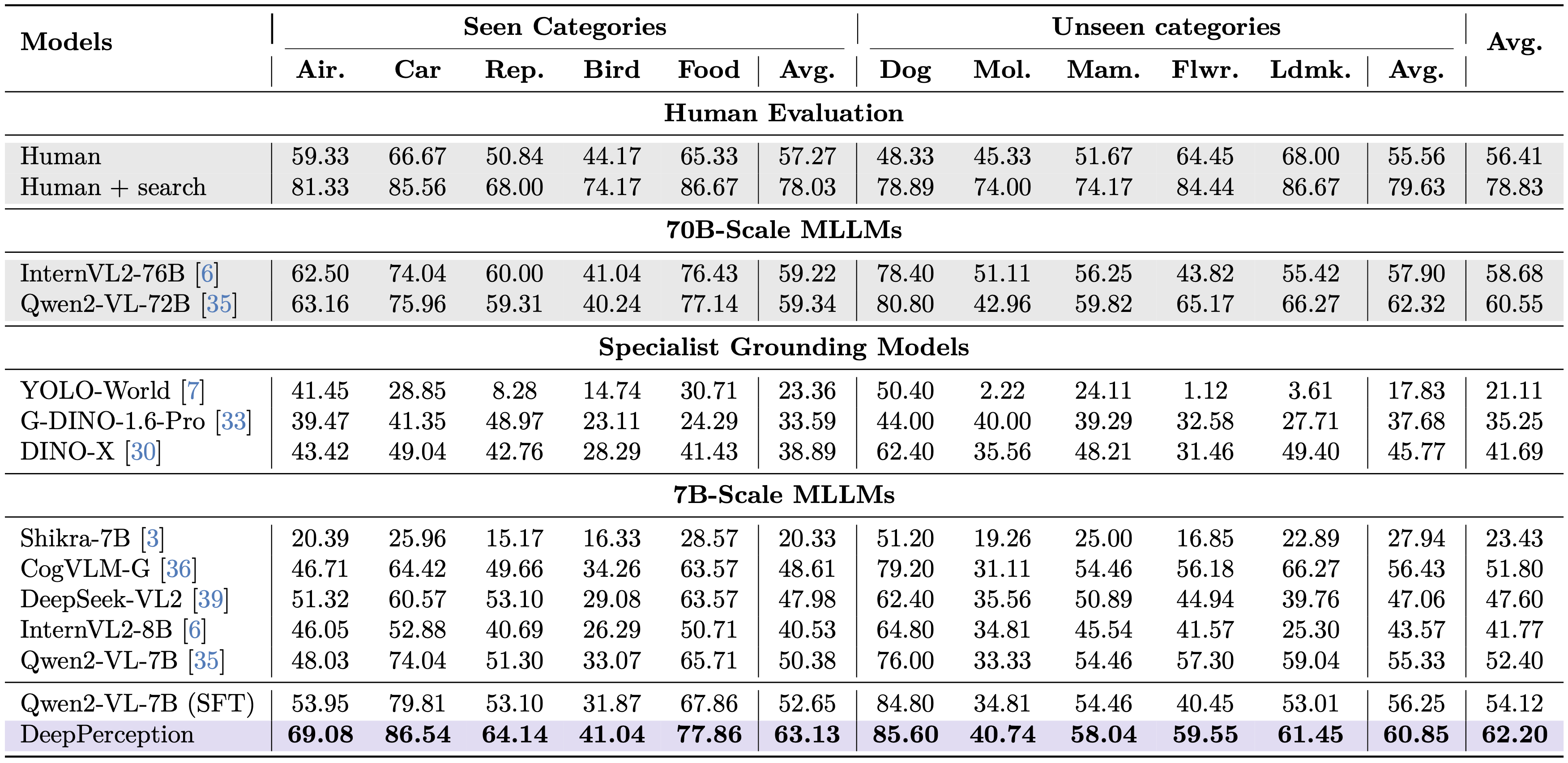
Table 1: KVG-Bench reults of DeepPerception and baseline models.
As demonstrated in Tab. 1, our DeepPerception model achieves significant performance improvements by integrating cognitive visual perception capabilities, validating the hypothesis that human-inspired cognition-perception synergy enhances visual perception. On in-domain categories, DeepPerception attains 63.13% average accuracy, surpassing all 7B-scale baselines (e.g., +10.5% over SFT) and outperforming 70B-scale models such as InternVL2-Llama3-76B (59.22%). For out-of-domain generalization, it achieves 60.85% accuracy—comparable to 70B-scale models—while demonstrating near-human performance in categories where the model possesses richer knowledge, such as Dog (85.60% vs. human evaluators’78.89%).
These results confirm that DeepPerception’s success stems from its ability to emulate human-like cognitive processes: iterative knowledge-guided reasoning refines perceptual hypotheses (e.g., verifying anatomical features stepwise), while reinforcement learning aligns these hypotheses with precise visual outputs. The consistent superiority over non-cognitive baselines, particularly in fine-grained categories like Car (86.54% vs. human 85.56%), proves that structured knowledge integration—not mere visual memorization —drives performance gains. By bridging knowledge reasoning with perception, DeepPerception establishes new state-of-the-art results on KVG-Bench, demonstrating that cognitive mechanisms central to biological vision can be effectively operationalized in multimodal AI systems.
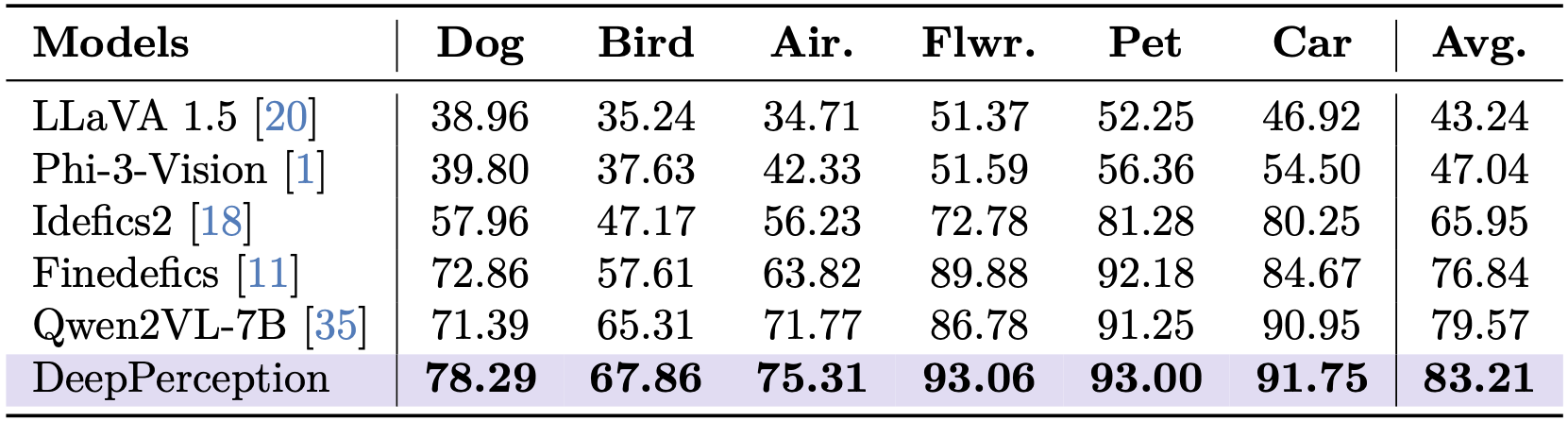
Table 2: FGVR reults of DeepPerception and baseline models.
To validate the generalizability of cognitive visual perception, we conducted experiments on FGVR datasets. Unlike the two-stage training paradigm used for KVG, only the reinforcement learning phase was applied here, as base models already exhibit strong baseline performance on FGVR. As shown in Tab. 2, our DeepPerception model achieves state-of-the-art results across all categories, demonstrating universal performance gains: DeepPerception achieves state-of-the-art results across all FGVR categories (83.21% average accuracy), outperforming Qwen2-VL-7B by +3.64%. This evidence strongly supports that cognitive visual perception, characterized by iterative knowledge-visual alignment, provides universal benefits for fine-grained perception, mirroring human experts’ ability to combine sensory input with conceptual understanding.

Table 3: Performance Comparison of DeepPerception and Qwen2VL-7B on general multimodal benchmarks.
To comprehensively assess the model’s general capabilities across diverse multimodal scenarios, we conducted evaluations on established multimodal benchmarks. As shown in Tab. 3, DeepPerception maintains performance comparable to the base model, demonstrating preserved general capabilities without degradation.
Analysis
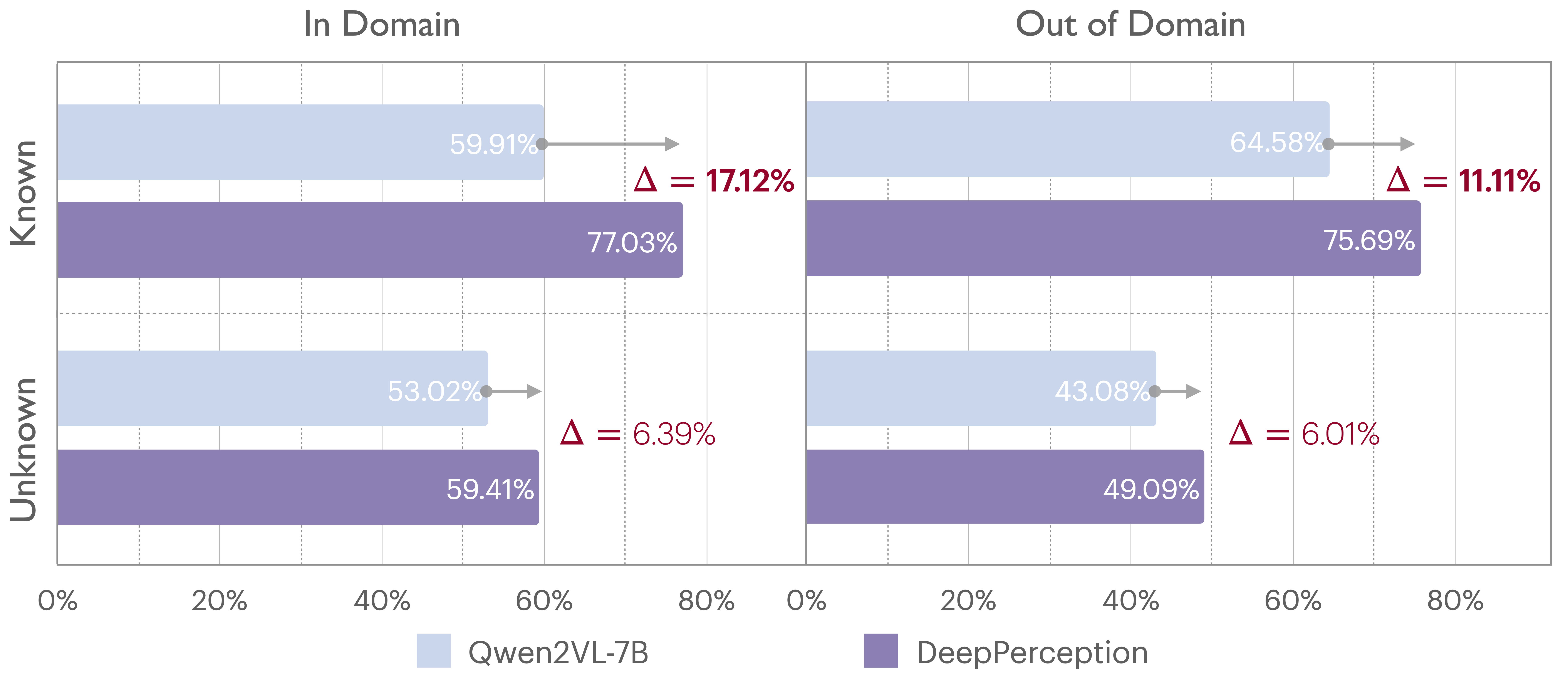
Figure 5: Knowledge evaluation results.
How knowledge influences perception. We systematically evaluated the base model’s knowledge by probing entity-specific discriminative features and validating factual alignment against Wikipedia references using Qwen2.5-14B. Entities were then classified into four groups based on knowledge possession (Known/Unknown) and training data presence (in-domain/out-of-domain). As evidenced in Fig. 5, DeepPerception achieves significantly greater performance gains on known entities versus unknown entities regardless of domain boundaries, confirming that its improvements originate from knowledge-driven cognitive processing rather than superficial perceptual enhancements, thereby validating its capacity to harness domain knowledge for visual perception. This aligns with human experts’ reliance on domain expertise to resolve ambiguity, confirming our framework’s success in emulating cognitive visual perception.
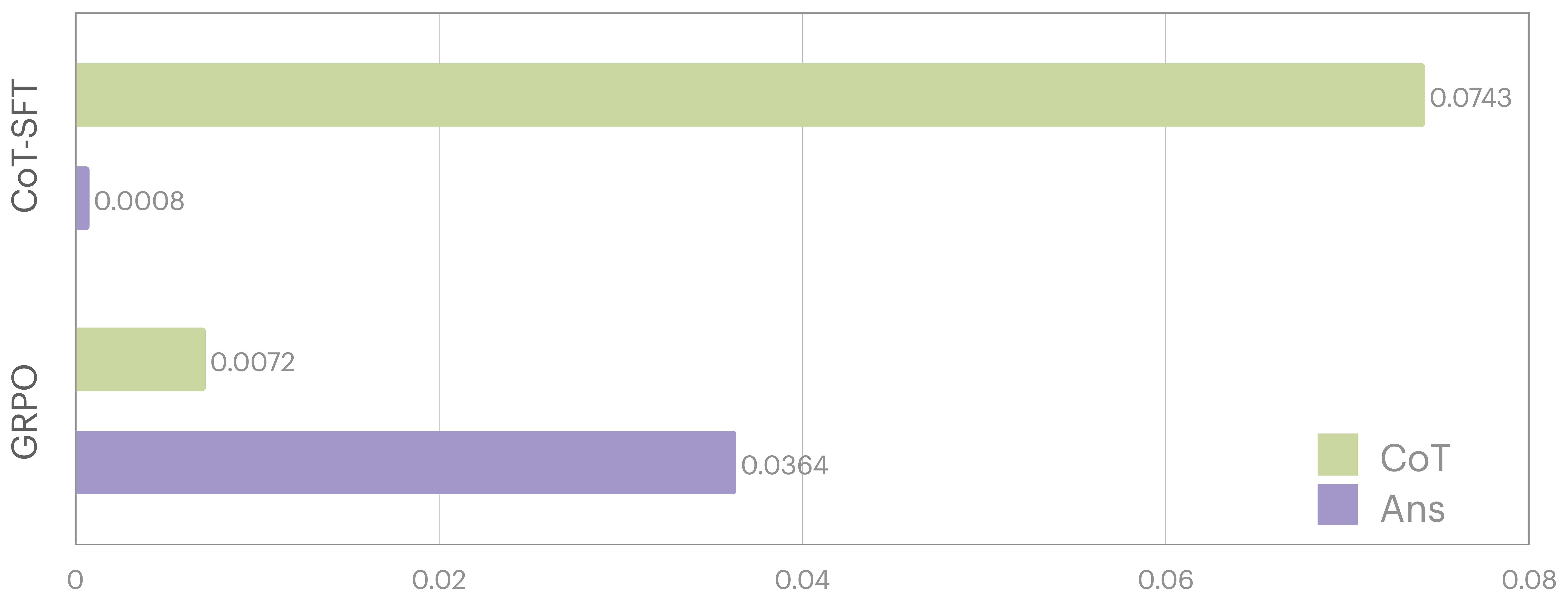
Figure 6: KL Divergence analysis.
The roles of CoT-SFT and GRPO. As shown in Fig. 6, we quantified the impact of our two-stage training paradigm by measuring the KL Divergence between stage-2 models (trained with CoT-SFT or GRPO) and the stage-1 model, separately evaluating the CoT and answer components. For CoT-SFT, the significantly higher KL Divergence in the CoT components versus answer segments indicates that CoT-SFT primarily equips the model with perception-oriented reasoning capabilities. In contrast, GRPO exhibited greater divergence in the answer components than in the CoT, demonstrating its focus on refining perceptual accuracy grounded in the reasoning process. By combining the two stages, the framework achieves synergistic enhancement of cognitive visual perception, effectively bridging knowledge-driven reasoning and sensory processing.
Discussion
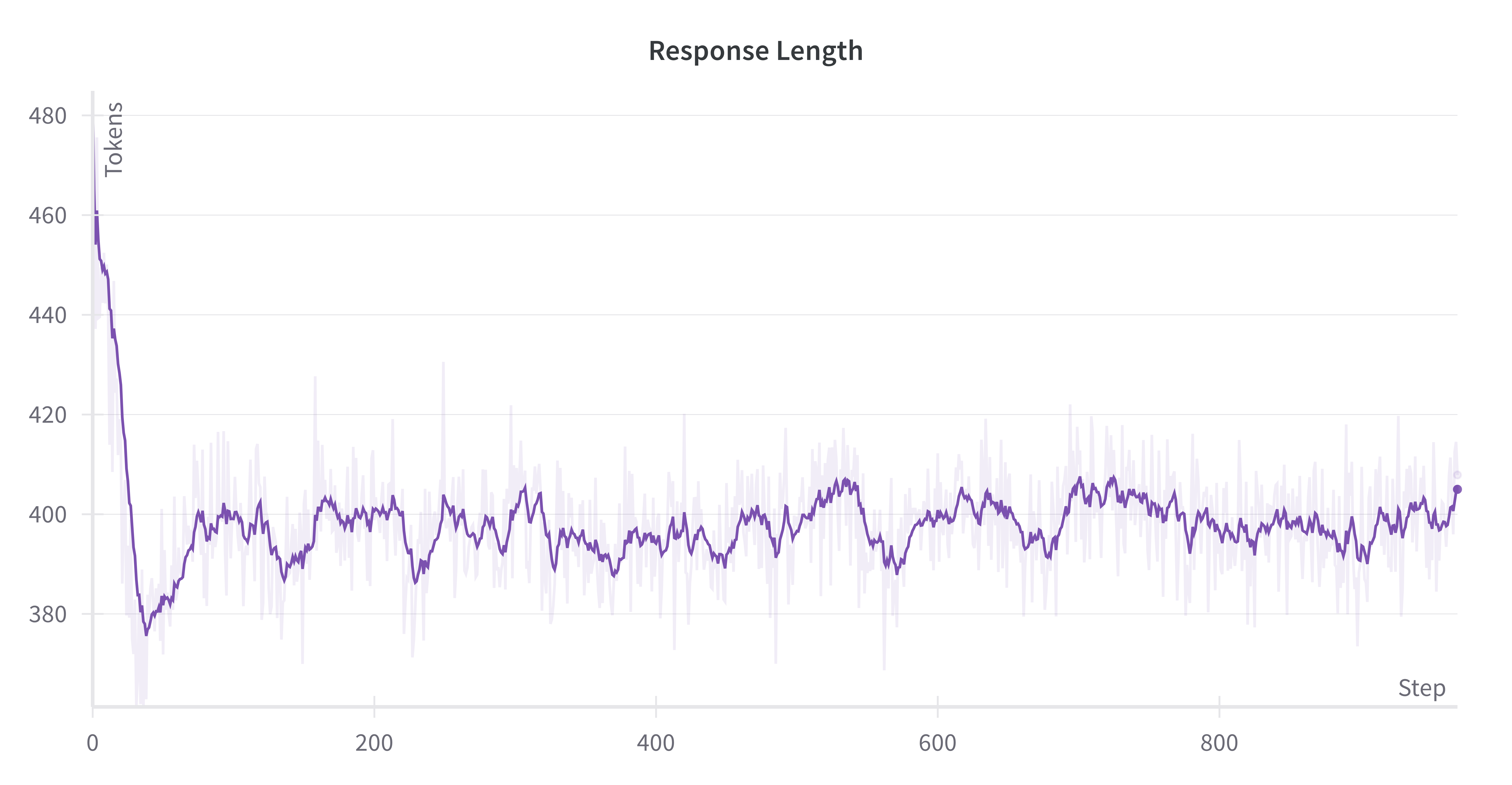
Figure 7 (a): The average response length of DeepPerception on the KVG training data during the GRPO process.
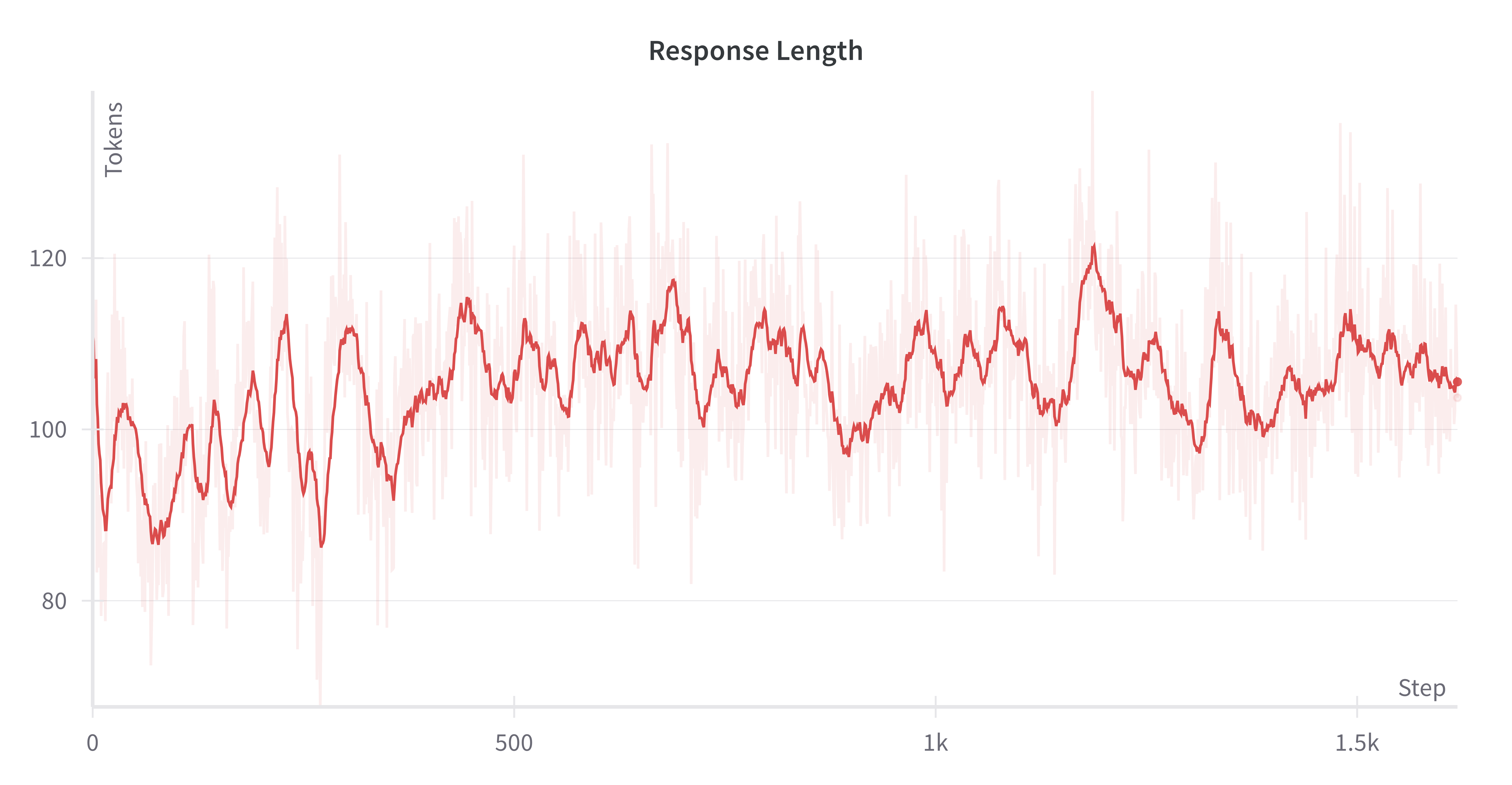
Figure 7 (b): The average response length of DeepPerception on the FGVR training data during the GRPO process.
We discuss two empirical findings of GRPO, with detailed results provided in the appendix: (1) Unlike DeepSeek-R1-Zero’s progressive increase in response length during training, GRPO training on both KVG and FGVR data exhibits stable completion lengths fluctuating within specific ranges, suggesting bounded reasoning complexity in visual perception tasks; (2) We observed instances where incorrect cot rationales led to correct answers, indicating that the presence of cognitive processes, rather than their length or even factual accuracy, is the primary determinant of performance improvement.
Qualitative Results

Figure 8 (a): Case study (Whippet) comparing DeepPerception and Qwen2-VL-7B on KVG-Bench.

Figure 8 (b): Case study (Lockheed Martin F-22 Raptor) comparing DeepPerception and Qwen2-VL-7B on KVG-Bench.

Figure 8 (c): Case study (Cherolet Express) comparing DeepPerception and Qwen2-VL-7B on KVG-Bench.

Figure 8 (d): Case study (Croque madame) comparing DeepPerception and Qwen2-VL-7B on KVG-Bench.

Figure 8 (e): Case study (Tarentola mauritanica) comparing DeepPerception and Qwen2-VL-7B on KVG-Bench.

Figure 9 (a): Case study (727-200) comparing DeepPerception and Qwen2-VL-7B on FGVR.

Figure 9 (b): Case study (Rusty Blackbird) comparing DeepPerception and Qwen2-VL-7B on FGVR.

Figure 9 (c): Case study (Audi TT RS Coupe 2012) comparing DeepPerception and Qwen2-VL-7B on FGVR.

Figure 9 (d): Case study (alpine sea holly) comparing DeepPerception and Qwen2-VL-7B on FGVR.

Figure 9 (e): Case study (Maine Coon) comparing DeepPerception and Qwen2-VL-7B on FGVR.
Citation
@misc{ma2025deepperception,
title={DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding},
author={Xinyu Ma and Ziyang Ding and Zhicong Luo and Chi Chen and Zonghao Guo and Derek F. Wong and Xiaoyi Feng and Maosong Sun},
year={2025},
url={https://arxiv.org/abs/2503.12797},
}